


Deep Learning methods applied to computer vision task solve problems with previously unimaginable precision, for instance in semantic segmentation and object recognition. Perhaps the major drawback of deep neural networks is their excessive need for computational power. Especially inference, i.e. applying a trained model on new data, is usually constrained by low latency and low power usage requirements. No end user would carry around power hungry GPU’s along with their smartphone to get the ideal camera settings for the best picture. In the same way, an autonomous car will not be able to spend 500ms for detecting a pedestrian.
With this motivation behind I participated in the seminar on Hardware Acceleration for Machine Learning and presented a paper from the Energy Efficient Multimedia Group at MIT from Professor Sze. Her group developed an application-specific integrated circuit (ASIC) for low-power inference of deep neural networks. Below I share the presentation as well as a summary of the paper structured as suggested in [1]. Please let me know if you want to use any of the provided material.

A review of Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices [2]
1 Summary
Eyeriss v2 is the second major design iteration of Eyeriss, an ASIC for accelerated inference of Deep Neural Networks (DNNs) on mobile devices. The focus has been extended from efficiency, latency, flexibility to scalability as well. To achieve strong scaling in the number of process elements, Eyeriss v2 introduces a new communication infrastructure connecting the Processing Elements (PEs). Furthermore, an enhanced version of the PE is presented, which allows to process the Multiply and Accumulate (MAC) operations in the compressed domain, exploiting zeros in weights and input activations (iacts). Remarkably this does not only result in better energy efficiency due to less data transferred, but in better latency as well, by actually skipping the zero operations.
1.1 Motivation
Various breakthroughs in DNN based computer vision or speech recognition have undoubtedly shown the potential of deep learning in perception and scene understanding. An often cited example is the ImageNet Challenge [3], in which AlexNet in 2012 and then ResNet in 2016 have impressively demonstrated the power of DNNs, see [4] for a broader introduction.
In order to fully exploit these new capabilities, it is crucial to pursue edge processing, i.e. inference on the end-user device. Remote processing in the cloud has clear limitations, such as data privacy, mobile network availability and mobile data usage issues. Most importantly however, availability and latency are crucial in safety critical processes such as autonomous driving or robot control.
On mobile devices, the available energy is limited. This requires the processing units to be as energy efficient as possible. The importance of range in electric cars or battery duration in mobile phones illustrates this need.
Modern DNNs show a remarkable variety in filter sizes, number of channels and sparsity across their layers. As the technology is under intense development, there are almost no assumptions that can be made on the architectural level. Therefore any accelerator needs to be flexible enough to support current and perhaps future architectures.
It is important to emphasize, that accuracy is the main driver in the deployment of DNNs. In most cases there is hence only little margin for the accelerators to trade-off for better efficiency /latency gains.
1.2 Contribution
The main contribution of Eyeriss v2 is a novel Network on chip (NoC), featuring high flexibility from high bandwidth, low spatial data reuse scenarios to low bandwidth, high spatial data reuse opportunities. This change from a flat multicast network in Eyeriss v1 to a hierarchical mesh increases throughput in MobileNet by 5.6 × and energy efficiency by 1.8× [2].
The PE is redesigned to implement a small pipeline, processing the data in the Compressed Sparce Column (CSC) format and actively skipping the zero terms. For sparse networks this can result in an additional 20 % to 30 % improvement in energy efficiency and throughput.
For comparison and summary purposes, it is important to emphasize the row stationary dataflow, introduced already in Eyeriss v1 [5]. Even though this is not part of the paper, version 2 is built on top of this concept, which is an interesting point for comparison with related works.
1.2.1 Row Stationary dataflow
In a spatial architecture such as Eyeriss, with an array of processing elements, it can be challenging to distribute weights, iacts and partial sums (psums) on the array while minimizing data movements and maximizing local reuse. Each PE has a local register file where data is ideally stored and accessed multiple times, since access there shows the lowest energy consumption as well as the lowest latency, see the illustration below.
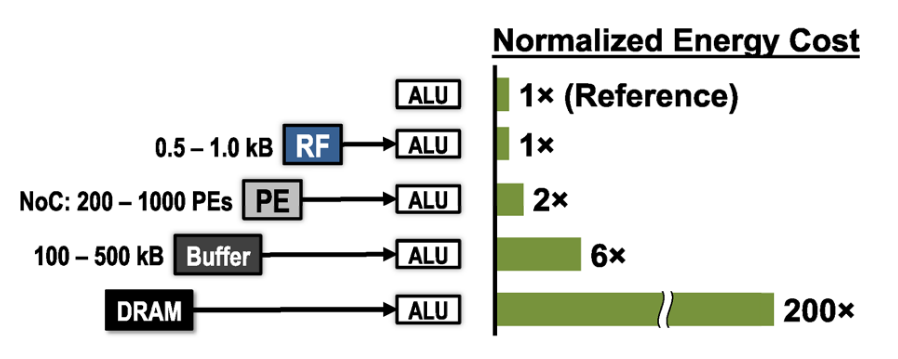
Perhaps the most intuitive way to accomplish this mapping for a neural network layer is storing the weights stationary on the PE, while letting iacts and psums flow through the array. This is called the weight stationary dataflow and minimizes the energy of reading weights.
Eyeriss v1, and v2 as well, implement the row stationary dataflow, which computes a 1-D convolution primitive by mapping the filter weights to each PE and accumulating the partial sum stationary in the PEs. In a sliding window fashion, the iacts propagate through the array. Higher dimensional convolutions are constructed out of the 1-D primitive, in the 2-D case for instance, the iacts are diagonally reused, and psums finally horizontally accumulated.
In contrast to other dataflow mappings, the row stationary approach does not individually optimize for a specific datatype, but instead optimizes the overall energy efficiency and achieves a reduction of at least 30 % in energy consumption with respect to other methods, see p. 2313 [4].
1.2.2 Hierarchical Mesh NoC
Like in Eyeriss v1, there are additional global buffers (GLBs) in place to add another layer in the memory hierarchy, before the system’s main memory. The communication between those GLBs and the PEs is handled by the novel NoC. Its hierarchical structure clusters the PEs and the GLBs in 8×2 subunits, with 12 PEs each. For each of the three datatypes, i.e. iacts, psums and weights, dedicated NoCs exist, each of which is tailored to their specific use. E.g. the weights routers directly read from main memory into the PEs without the need for a GLB cluster.
The hierarchical structure provides the significant advantage of reducing the needed routing elements to a feasible amount when scaling up the number of PE, while still providing all the needed flexibility. In a fully connected layer, for instance, the iacts can easily be broadcasted to all clusters, by interfacing just the top routers with each other. The weight on the other hand will be unicasted individually. This means that the weight routers will read from memory, each of them their respective value, without interfering with other clusters.
Besides the flexibility, which for instance extends also to depth-wise layers, the most important innovation is scalability. Scaling up from 256 PEs to 16384 PEs in Eyeriss v2 yields 57.4 × performance increase (out of ideal 64), whereas a scaled-up version of Eyeriss v1 only gets 1.37 × better. Version 2 passes therefore from no scaling to almost ideal strong scaling.
1.2.3 Sparse PE Architecture
The challenging task of fully exploiting sparse architectures is solved by performing all the processing in a special compressed CSC format, aiming to feed the PEs already in the best possible format.
A seven stage pipeline is implemented in every PE, to maintain throughput in case of zero reads, and to handle read dependencies, i.e. a non-zero weight is only read for a non-zero iact. Furthermore the PE is extended to support Single Instruction Multiple Data (SIMD), since the area and power used for calculations in a single PE has become insignificant with respect to the other elements. In this way 2 elements are processed at once.
1.3 Methodology
The authors carried out the design for a 65 nm CMOS process. For evaluation and design iterations, a cycle-accurate gate-level simulation was profiled using actual weights of DNNs and data from the ImageNet dataset. The results containing a comparison with Eyeriss v1, are performed with a scaled version of Eyeriss v1 to match the number of PEs of v2.
Eyeriss v1 was physically realized and used in connection with an Nvidia Jetson board. Both chips process layer by layer and get reconfigured in between, i.e. the mapping paths are set. It is for instance unveiled that pooling layers are not processed by Eyeriss v2. They would most likely rely on similar companion boards to process such steps.
1.4 Results
Both energy efficiency and throughput is considerable higher with respect to Eyeriss v1. In comparison to other work, one can note that some competitors, such as [6] show more energy efficient results. However, those implementations seem to be more specialized, e.g. can not compute fully connected layers. Furthermore, according to the authors, there is no other work currently presenting results for both, sparse and dense DNNs.
1.5 Conclusion
Beyond the performance improvement over Eyeriss v1, this work introduces a flexible hierarchical NoC design, which mitigates the common issues with strong bandwidth assumptions for specific datatypes. Furthermore, a new PE architecture is presented, able to truly exploit sparsity in DNNs by translating it to energy efficiency and throughput improvements.
2 Critique
In general, the authors have shown to pursue a strict design methodology, basing their choices on actual energy aware measures, e.g. energy aware pruning, row stationary dataflow. The simulation approach makes it possible to attempt an isolated impact measure of the NoC and the sparse PE architecture. For this purpose Eyeriss v1 is scaled up to have the same number of PEs, although it is known to not scale well. This makes it also difficult to compare results across the two publications.
In the comparison table with prior works, the authors do not highlight the accuracy drop that might arise when using the sparse networks version. One possible reason might be the lack of data from prior works. However, this lack of data makes it particularly challenging to objectively compare different architectures of DNN accelerators.
Overall, the architecture seems very hand crafted. For instance the advantage they highlight of using a 2×8 router cluster, (i.e. a rectangular shape with width 2), resulting in 3 instead of 4 ports, might vanish when scaling up. From this perspective, the design space seems to be explored just loosely, and the effect of having a larger PE arrays or scaling up the top level routers, i.e. more clusters, is not emphasized.
Furthermore, it remains unclear how this could be extended. For instance, the missing pooling layer implementation is not explicitly justified. The software procedure to generate the 2134-bit long mapping command remains also unclear. In general, the results might be difficult to reproduce.
3 Synthesis
An interesting candidate for comparison is project Brainwave [7]. For instance, the Brainwave system “typically pins DNN model weights in distributed on chip SRAM memories”, i.e. it uses a weight stationary dataflow. In this regard there might be potential for improvement in Brainwave, but this might have been changed already, since implementation details are not disclosed. Regarding the assumptions of connectivity, for edge processing, it is clear that not all applications will be able to rely on transmitting data for remote processing as discussed before. From this perspective there is a clear need for edge processing chips such as Eyeriss.
Regarding the NoC, a related idea for Field Programmable Gate Arrays (FPGAs) is discussed in Xilinx [8]. The issue they try to alleviate is the bitwise communication control commonly applied in FPGAs. This flexibility limits the computation resources, whereas the NoC would require to use common byte streams, and could flexibly interface with memory. This flexibility is also crucial in Eyeriss, and even enhanced by using a hierarchical mesh. The mentioned issue of a mesh being expensive is mitigate in the Eyeriss v2 implementation by adding another hierarchical level.
Another paper in a related topic is FixyNN [9]. The goal is again to improve energy efficiency to enable edge processing, however the approaches are rather different. Whereas Eyeriss provides a layer-wise DNN processor, with a considerable flexibility from dense to sparse layers, calculating effectively the whole network, FixyNN tries to create specialized hardware for common first layers. The multiplication is thereby replaced by bit shifting through hard wiring at development stage. This means that only fixed weights for a shared frontend are accelerated. Although recently it has become increasingly popular to use pretrained frontends, at hardware level, the lack in flexibility constitutes a major drawback in this design, as well as performance losses.
References
- [1]P. W. L. Fong, “Reading a computer science research paper,” SIGCSE Bull., pp. 138–140, Jun. 2009, doi: 10.1145/1595453.1595493.
- [2]Y. Chen, T. Yang, J. Emer, and V. Sze, “Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9. pp. 292–308, 2019.
- [3]O. Russakovsky et al., “ImageNet Large Scale Visual Recognition Challenge,” Int J Comput Vis, pp. 211–252, Apr. 2015, doi: 10.1007/s11263-015-0816-y.
- [4]V. Sze, Y. Chen, T. Yang, and J. S. Emer, “Efficient Processing of Deep Neural Networks: A Tutorial and Survey,” Proceedings of the IEEE, vol. 105. pp. 2295–2329, 2017.
- [5]Y. Chen, T. Krishna, J. S. Emer, and V. Sze, “Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks,” IEEE Journal of Solid-State Circuits, vol. 52. pp. 127–138, 2017.
- [6]J. Lee, C. Kim, S. Kang, D. Shin, S. Kim, and H. Yoo, “UNPU: A 50.6TOPS/W unified deep neural network accelerator with 1b-to-16b fully-variable weight bit-precision,” in 2018 IEEE International Solid – State Circuits Conference – (ISSCC), 2018, pp. 218–220.
- [7]J. Fowers et al., “A Configurable Cloud-Scale DNN Processor for Real-Time AI,” in 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), 2018, pp. 1–14.
- [8]B. Gaide, D. Gaitonde, C. Ravishankar, and T. Bauer, “Xilinx Adaptive Compute Acceleration Platform: VersalTM Architecture,” in Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2019, pp. 84–93, doi: 10.1145/3289602.3293906.
- [9]P. N. Whatmough, C. Zhou, P. Hansen, S. Kolala Venkataramanaiah, J. Seo, and M. Mattina, “FixyNN: Efficient Hardware for Mobile Computer Vision via Transfer Learning.” 2019.